Go Goroutine原理
线程调度
- 进程:资源分配的基本单位
- 线程:调度的基本单位
- 无论是在线程还是进程,在Linux都是task_struct描述,从内核角度来看,与进程无本质区别
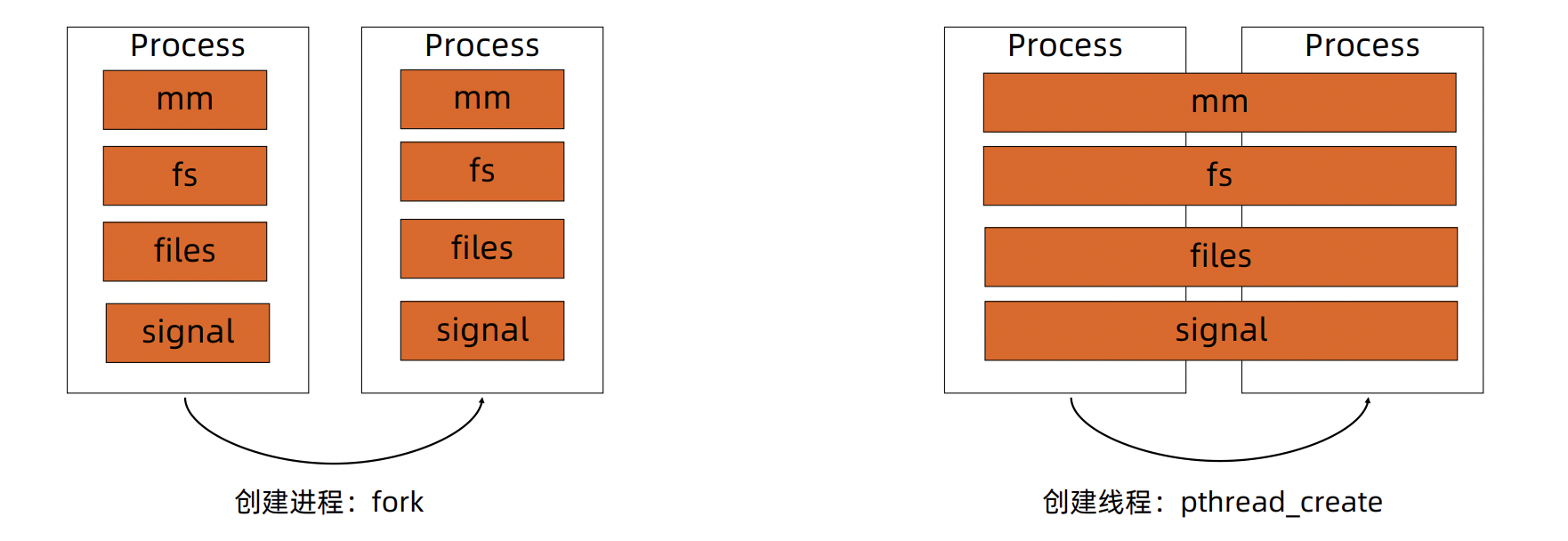
Liunx中创建线程就相当于是创建进程,只不过内存、文件等信息进行共享
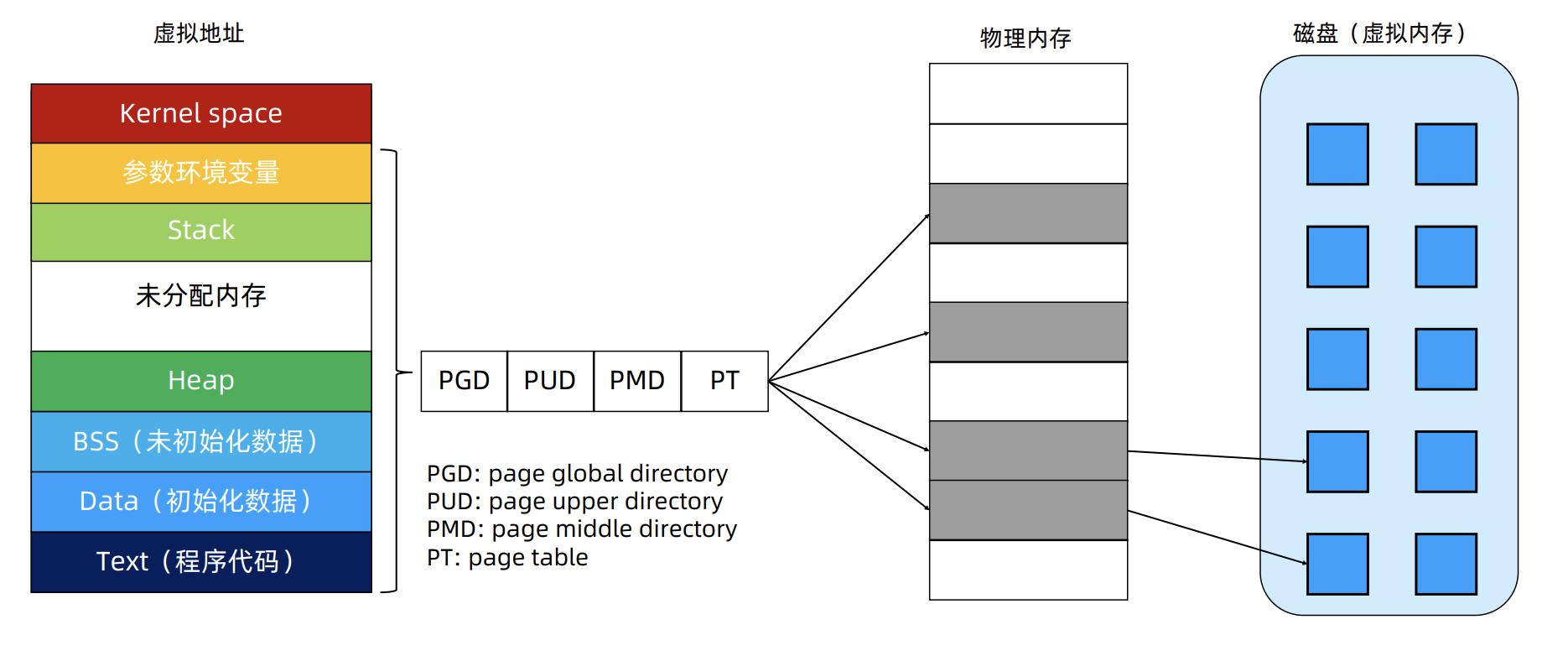
Linux进程的内存使用
1 | |
为何栈向下生长,堆向上生长
每一个可执行可编译程序,从低地址到高地址依次是:text、data、bss、堆、栈、环境参数变量;其中堆和栈之间有很大的地址空间空闲着,在需要分配空间的时候,堆向上涨,栈往下涨
这样设计可以使得堆和栈能够充分利用空闲的地址空间,一个向上涨,一个向下涨,这样它们就可以最大程度地共用这块剩余的地址空间,达到利用率的最大化
CPU对内存的访问
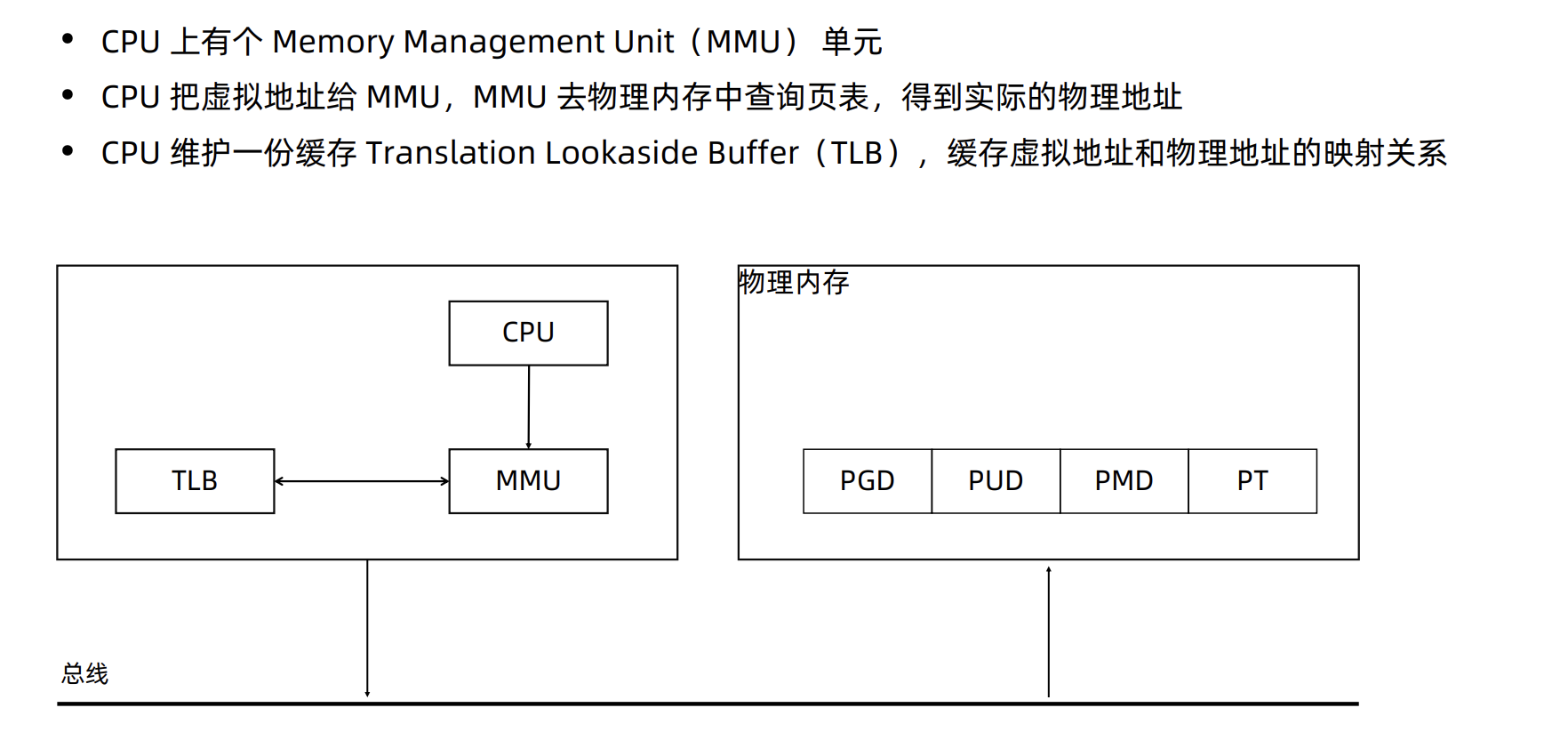
这样就进行的内存交换(通过查页表找映射关系),将磁盘上的虚拟内存交换到物理内存上
进程和线程切换的区别
进程切换开销
- 直接开销
- 切换页表全局目录(PGD)
- 切换内核态堆栈
- 切换硬件上下文(进程恢复前,必须装入寄存器的数据统称为硬件上下文)
- 刷新 TLB
- 系统调度器的代码执行
- 间接开销
- CPU 缓存失效导致的进程需要到内存直接访问的 IO 操作变多
线程切换开销
- 线程本质上只是一批共享资源的进程,线程切换本质上依然需要内核进行进程切换
- 一组线程因为共享内存资源,因此一个进程的所有线程共享虚拟地址空间,线程切换相比进程切换,主要节省了虚拟地址空间的切换
用户线程
无需内核帮助,应用程序在用户空间创建的可执行单元,创建销毁完全在用户态完成
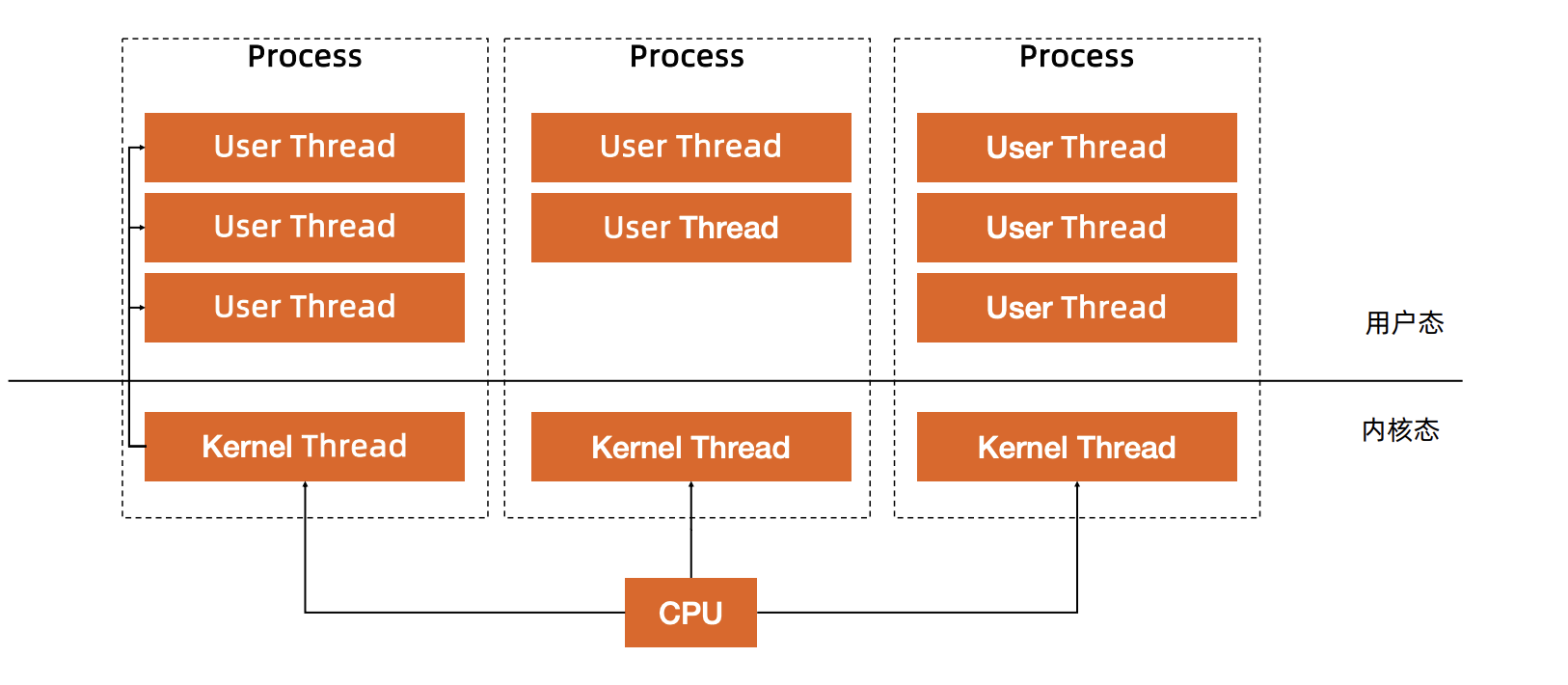
在程序的层面一次执行,无需通过系统调用的方式进行切换,一旦拿到时间片就尽可能的使用,减少对系统调用的依赖
Goroutine原理
Go 语言基于 GMP 模型实现用户态线程
goroutine和线程的区别
内存占用
创建一个goroutine的栈内存消耗为2KB,运行过程中,如果栈空间不够,会自动扩容
创建一个thread为了避免极端情况下操作系统线程栈的溢出,默认会为其分配一个较大的栈内存(1-8MB),而且还需要一个被称为“guard page”的区域用于和其他thread的栈空间进行隔离(防止线程1因为栈溢出后污染了相邻的线程2,因为地址空间是相连的)。而栈内存空间一旦创建和初始化完成之后其大小就不能再有变化,这决定了在某些特殊场景下系统线程栈还是有益处的风险
创建/销毁
线程创建和销毁都会有巨大的消耗,是内核级的交互,而进入内核所消耗的性能代价比较高,开销较大
goroutine是用户态线程,是由goroutine管理,创建和销毁的消耗非常小
用户态和内核态
调度切换
抛开陷入内核,线程切换会消耗1000-1500纳秒(上下文保存成本高,较多寄存器,公平性,复杂时间计算统计),一个纳秒平均可以执行12-18条指令
所以由于线程切换,执行指令的条数会减少12000-18000。goroutine的切换约为200ns(用户态,3个寄存器),相当于2400-3600条指令。因此,goroutine切换成本比thread小得多
复杂性
线程的创建和退出复杂,多个thread间通讯复杂(share memory)
不能大量创建线程,成本高,使用网络多路复用,存在大量callback。对于应用服务线程门槛高,例如需要做第三方库隔离,需要考虑引入线程池等
GMP调度模型
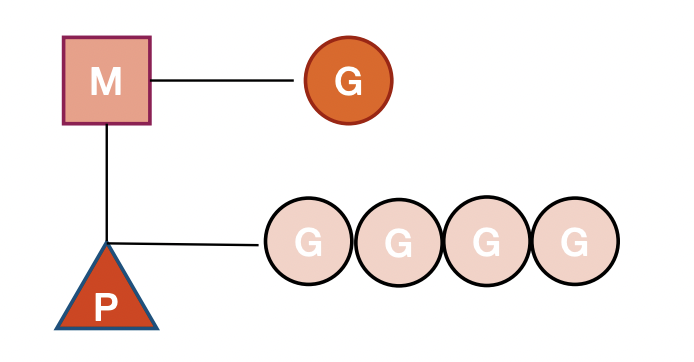
G:goroutine的缩写,每次go func( )都代表一个G,无限制
每个 goroutine 都有自己的栈空间, 定时器,初始化的栈空间在 2k 左右,空间会随着需求增长
M:工作线程(OS thread)也被称为Machine,使用struct runtime.m,所有M是有线程栈的
抽象化代表内核线程,记录内核线程栈信息,当 goroutine 调度到线程时,使用该 goroutine 自己的栈信息
P:“Processor” 代表调度器,负责调度 goroutine,维护一个本地 goroutine 队列,M 从 P 上获得 goroutine 并执行,同时还负责部分内存的管理
它代表了M所需要的上下文环境,也是处理用户级代码逻辑的处理器,它负责衔接M和G的调度上下文(相当于一个队列,不停的从里面捞G来执行),将等待执行的G与M对接,当P有任务时需要创建或者唤醒一个M来执行它队列里的任务。所以P/M需要进行绑定,构成一个执行单元
P决定了并行任务的数量,可通过 runtime.GOMAXPROCS 来设定。在GO1.5之后 GOMAXPROCS 被默认设置CPU数量,而之前则默认是1
其中G相当于是用户线程,M相当于是内核线程数量,是可以大于P的(上限10000),建立的P(上限是256)是和CPU数量是对应的
这样做的目的是M可能陷入系统调用,而系统调用可能是阻塞的,比如磁盘读取,这个时候CPU是空闲的,创建新的M与P关联,可以让更多的G被调度,充分利用CPU
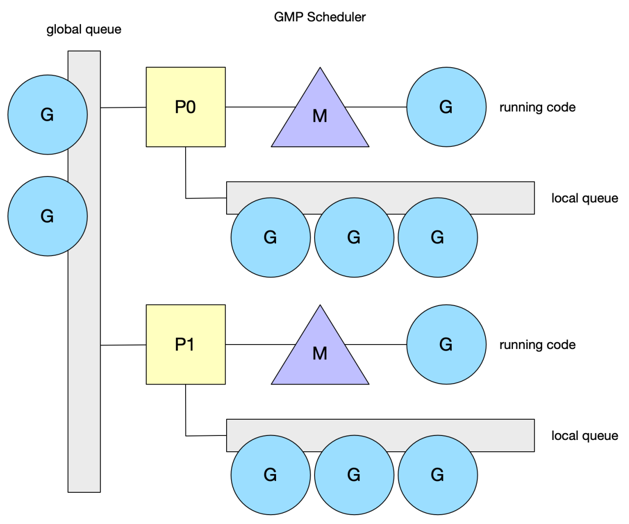
调度
Go的调度本质上就是一个生成—消费模型,将消息写入队列再从队列中取出消息
gouroutine生产端
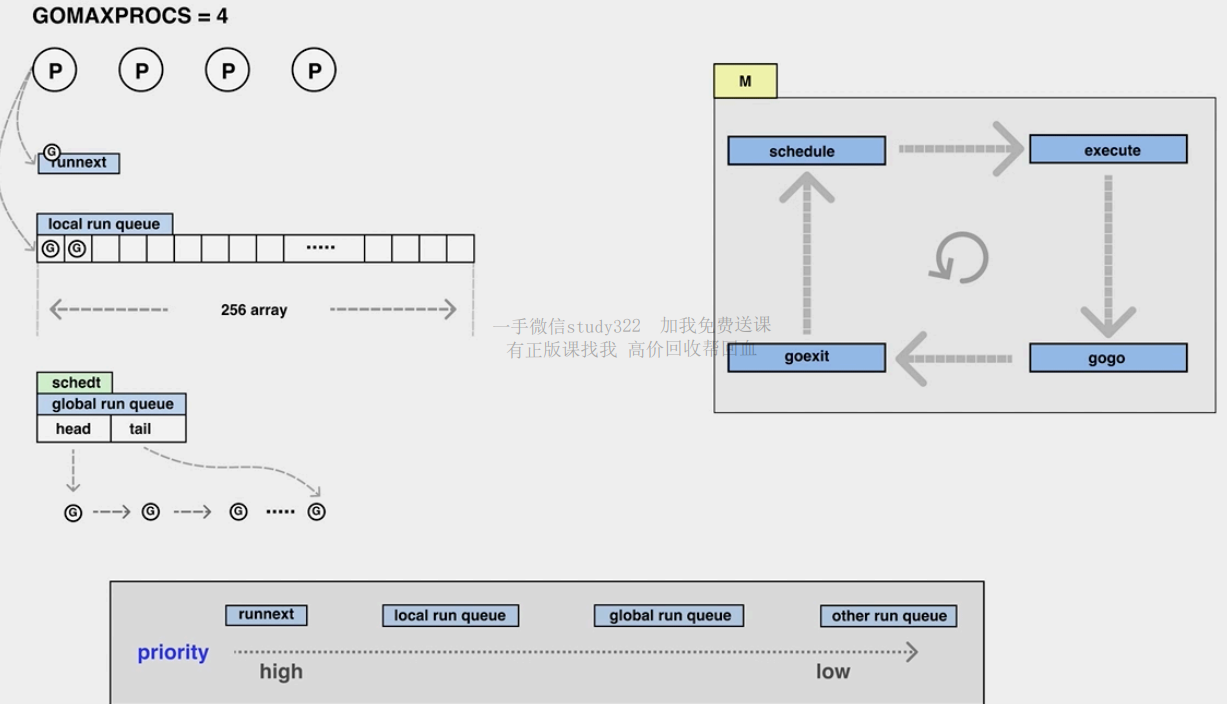
有三个队列,优先级最高的是runnext(只能存一个值的队列,最快)
其次就是local queue(数组,限制了大小(256),本地用数组访问的快,局部性原理,新来的优先级一定比老的高) 和global queue(链表,无限扩张)
每次启动一个goroutine就现将任务放入runnext,如果runnext满了就将runnext原来的task踢到local queue中(默认新进来的goroutine优先级最高,最先处理),如果runnext和local queue都满了,就将原来runnext中的task和local queue中一半的task拿出来拼成一个链表存到global queue
goroutine消费端
M执行循环调度,必须与一个P绑定
在local中 (优先在runnext中拿) 执行60次(先去本地队列里捞,就可以减少使用全局队列的锁,提高吞吐量。再去全局队列里捞,因为用全局队列会上锁),就要去global (要加锁) 中执行1次(最多拿本地队列一半长度的goroutine),还是没有就work-stealing (去其他队列里拿任务,拿一半),如果还是没有就进入休眠状态
work-stealing
M绑定的P没有可执行的goroutine时它会去按照优先级去抢占任务
先1/61的时间去全局队列里找 (防止全局队列里饥饿),然后去本地队列找,然后去其他M里找 (防止本地队列里饥饿)
找到任何一各任务,切换调用栈执行任务,再循环不断的获取任务,直到进入休眠
其核心思想就是避免饥饿 (其他进程都有事做,自己没有事做)
为了保证公平性,从随机位置上的P开始,而且遍历的顺序也随机化了(选择一个小于GOMAXPROCS,且和它互为质数的步长),保证遍历的顺序也随机化了
Spining thread
线程自旋是相对于线程阻塞而言的,表象就是循环执行一个指定逻辑(就是上面提到的逻辑,目的是不停的寻找G)。这样做的问题显而易见,如果G迟迟不来,CPU会白白浪费性能在这无意义的计算上。但好处也很明显,降低了M的上下文切换成本(不断睡眠和唤醒是需要消耗成本的),提高了性能
- M带P的找G执行
- M不带P的找P挂载
- G创建有没spiningM唤醒一个M
Go的设计者倾向于高性能的并发表现选择了后者。当然前面也提到过,为了避免浪费过多的资源,自旋的线程数不会超过GOMAXPROCS,这是因为一个P在同一时刻只能绑定一个M,P的数量不会超过GOMAXPROCS,自然被绑定的M的数量也不会超过。对于未绑定的游离态的M,会进入休眠状态阻塞
Syscall
Go有自己封装的syscall(系统调用),也就是进入和退出syscall的时候执行entersyscall/exitsyscall,也只有封装了系统调用才有可能触发重新调度,它将改变P的状态为syscall
系统监视器 (system monitor),称为sysmon,会定时扫描,在执行系统调用时,如果某个P的G执行超过了一个sysmon tick,就会脱离M
P和M脱离后目前在idle list中等待被绑定。而syscall结束后M按照如下规则执行直到满足其中一个条件
- 尝试获取同一个P,恢复执行G
- 尝试获取idle list中空闲P
- 把G放回global queue,M放回idle list
Sysmon
Go1.4后的异步抢占,注册sigurg信号,通过sysmon检测,对M对应的线程(运行超过10ms)发送信号,触发注册的handler,它往当前G的PC中插入一条指令(调用某个方法),暂停当前goroutine,在处理完handler,G恢复后,自己把自己推到global queue中
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!