Go逃逸分析
前言
最近在优化公司之前实习生写的后端代码,在db层这里
1 | |
当时觉得只是创建,则不需要传结构体指针,并且觉得传了指针后引起内存逃逸,增加GC压力,后续中总觉得是传指针可能不一定就会引发内存逃逸,则查阅了相关资料和自己之前做的笔记,对此情况做一个详细的说明
堆和栈
Go有两个地方可以分配内存:一个全局堆空间用来动态分配内存 (new make),另一个是每个goroutine都有的自身栈空间(初始是2k)
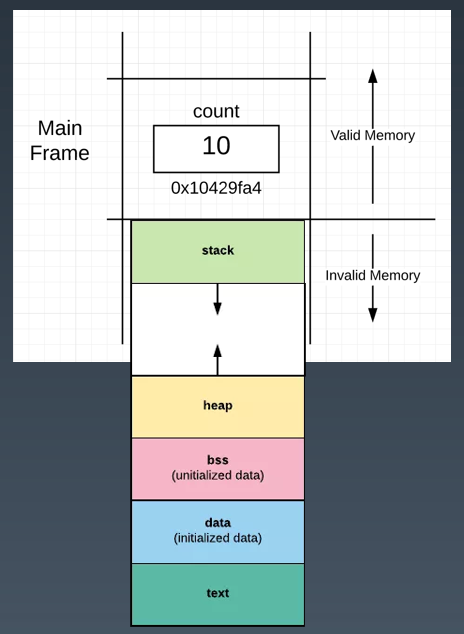
栈
栈区内存一般由编译器自动进行分配和释放,其中存储着函数的入参以及局部变量,这些参数会随着函数的创建而创建,函数的返回而销毁(通过CPU push & release )
堆
堆区的内存一般由编译器和工程师自己共同进行管理分配,交给 Runtime GC 来释放。堆上分配必须找到一块足够大的内存来存放新的变量数据。后续释放时,垃圾回收器扫描空间寻找不再被使用的对象
任何时候一个值出了一个函数的作用域,它就会被自动分配到堆上 (由编译器分析出来是否有逃逸行为)
栈分配廉价,堆分配昂贵
Go声明语法并没有提到栈和堆,而是交给GO编译器决定在哪分配内存,保证程序的正确性
逃逸分析
通过检查变量的作用域是否超出它所在的栈来决定是否将它分配在堆上的技术,其中变量的作用域超出它所在的栈这种行为即被称为逃逸。逃逸分析在大多数语言里属于静态分析:在编译期由静态代码分析来决定一个值是否能被分配在栈帧上,还是需要逃逸到堆上
- 减少GC压力,栈的变量,随着函数退出后系统直接回收,不需要标记后清除
- 减少内存碎片的产生
- 减轻分配堆内存的开销,提高程序的运行速度
Go语言虽然没有明确说明逃逸分析规则,但是有以下几点准则,是可以参考的
- 逃逸分析是在编译器完成的,这是不同于jvm的运行时逃逸分析
- 如果变量在函数外部没有引用,则优先放到栈中
- 如果变量在函数外部存在引用,则必定放在堆中
可以通过 go build -gcflags -m xxx.go 命令来查看逃逸分析结果,其中-m 打印逃逸分析信息
逃逸案例
变量类型不确定
1 | |
因为fmt.Println的函数参数为interface类型,编译期不能确定其参数的具体类型,所以将其分配于堆上
暴露给外部指针
1 | |
变量所占内存较大
Go中常说的goroutine初始大小为2KB,就是指用户栈,而堆则会大很多,所以,为了不造成栈溢出和频繁的扩缩容,大的对象分配在堆上更加合理
变量大小不确定
1 | |
在make方法中,没有直接指定大小,而是填入了变量n,这时Go逃逸分析也会将其分配到堆区去。可见,为了保证内存的绝对安全,Go的编译器可能会将一些变量不合时宜地分配到堆上
发送指针或带有指针的值到channel中
在编译时,是没有办法知道哪个 goroutine 会在 channel 上接收数据。所以编译器没法知道变量什么时候才会被释放
在一个切片上存储或带有指针的值
1 | |
一个典型的例子就是 []*string。这会导致切片的内容逃逸。尽管其后面的数组可能是在栈上分配的,但其引用的值一定是在堆上
slice背后的数组被重新分配 (地址要改变)
1 | |
参考之前 Go切片在函数中的传递知,在切片作为参数传递时,如果append引发扩容就会重新分配底层数组的地址
slice 初始化的地方在编译时是可以知道的,它最开始会在栈上分配。如果切片背后的存储要基于运行时的数据进行扩充,就会在堆上分配
在interface类型上调用方法
在 interface 类型上调用方法都是动态调度的 —— 方法的真正实现只能在运行时知道
外部是否发生引用
1 | |
函数里的x变量在堆上分配,因为它在函数退出后依然可以通过global变量找到,虽然它是在函数内部定义的
指针逃逸的总结
指针必然发生逃逸的三种情况
在某个函数中
new或字面量创建出的变量,将其指针作为函数返回值,则该变量一定发生逃逸(构造函数返回的指针变量一定逃逸)被已经逃逸的变量引用的指针,一定发生逃逸
被指针类型的
slice、map和chan引用的指针,一定发生逃逸
指针必然不会逃逸的情况
指针被未发生逃逸的变量引用;
仅仅在函数内对变量做取址操作,而未将指针传出;
指针有一些情况可能发生逃逸,也可能不会发生逃逸
- 将指针作为入参传给别的函数;这里还是要看指针在被传入的函数中的处理过程,如果发生了上边的三种情况,则会逃逸;否则不会逃逸
结尾
现在说明在函数传参传指针不应定会发生内存逃逸,要结合实际情况,看函数中是否将参数传入
interface参数的函数中等理解逃逸分析一定能帮助写出更好的程序。知道变量分配在栈堆之上的差别,那么我们就要尽量写出分配在栈上的代码,堆上的变量变少了,可以减轻内存分配的开销,减小gc的压力,提高程序的运行速度
不要盲目使用变量的指针作为函数参数,虽然它会减少复制操作。但其实当参数为变量自身的时候,复制是在栈上完成的操作,开销远比变量逃逸后动态地在堆上分配内存少的多 (可能会发生逃逸)
尽量写出少一些逃逸的代码,提升程序的运行效率
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!